
Leveraging AWS Redshift for Data Engineering and Data Science: A Comprehensive Guide
The premier AWS OLAP data warehouse service.

2 petabytes. That is how large our data lake is right now. Redshift plays an integral role in our data mesh strategy, and once again our friendly neighborhood dinosaur has employed my services to tell you data scientists how your data actually gets into your jupyter notebook.
For anyone that is new around here, I am
, during the day I build the financial systems that move your money around. There is a good chance your money has flown through the pipes I built. My primary topics focus around building on AWS and data engineering. For today we are focusing on Redshift.NOTE: A post like this is typically for my premium subs only. However, today I am giving you freebie boys a taste of what the upper echelon is like. My premium subs are what keeps this publication alive.
AWS Redshift in Data Engineering
Introduction
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud provided by Amazon Web Services (AWS). It is designed to leverage large amounts of data from various data sources and perform fast, complex queries on them.
In the context of data engineering and data science, Redshift plays a crucial role due to its ability to query and process large volumes of data efficiently. Here's a brief overview of Redshift:
Scalability: Redshift is designed to scale with your needs. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This makes it suitable for businesses of all sizes. However, I wouldn’t recommend Redshift or a data lake for smaller businesses, just due to the economics.
Performance: Redshift uses columnar storage, data compression, and zone maps to reduce the amount of I/O needed to perform queries. AWS did crazy engineering to get Redshift into the performance behemoth it is today. The goal was to make it as good, and then better than oracle for this type of data warehouse work. Which I think they have accomplished.
Data Integration: Redshift integrates with various data formats, including structured and semi-structured data. It can connect with various data sources such as AWS S3, DynamoDB, and more. This makes it a versatile tool for data engineers.
Security: Redshift provides robust security features, including network isolation and segmentation using Amazon VPC, encryption of data at rest and in transit, IAM roles, and more. The integration with AWS IAM allows for granular permissions and controls to prevent unauthorized data access, which is my world is very important. Data security is on the forefront of every CISO’s mind these days.
Cost-Effective: With Redshift, you pay for what you use. It provides the option to pause and resume your clusters, allowing you to manage your costs effectively. Of course, with cloud, its only cheaper if you make it cheaper. Don’t assume that Redshift will be cheaper than X service or Y on-prem application. You must *make* it cheaper. Lucky for you though, i’ve already written about how to do this, as i’ve chopped off over 1m from our cloud bill.
Cloud Financial Management (Cloud FinOps)
·
hello avatars, celt here to tell you about Cloud FinOps or CFM. Controlling cloud costs has quickly become a hot topic in the cloud engineering community. You might have even seen it referenced when elon took over titter, article here. If you do not know what youre doing you can easily rack up an ugly bill with a cloud provider. Many people have horror stories like this, and AWS is notoriously bad at some of the cost controls and visibility when compared to Azure or GCP. I will be focusing on AWS but the majority of this post is applicable to any provider. AWS recently released this whitepaper:

and here is the ACTIONABLE guidance:
Saving Money in Cloud (read to save millions)

85 million dollars. turns out its expensive to operate a cloud environment in a highly regulated space. BUT this bill would have been MUCH higher if we did not implement cost-saving practices. Keep reading if you want to uncover these secrets your cloud provider wont tell you.
Turbo Note: Keeping cloud bills under control in this downturn is very important, and can be an easy way to build some political capital as it gives your management some more budget breathing room.
The importance of Redshift in data engineering and data science is significant due to its ability to handle large data volumes, perform complex queries quickly, and integrate with various data sources and tools. This allows businesses to make data-driven decisions more effectively and efficiently.
Understanding AWS Redshift
Redshift is built on a column-oriented database management system that connects to SQL-based clients and business intelligence tools, making data easy to manage and analyze. It uses columnar storage technology which improves I/O efficiency and parallelizes queries across multiple nodes. To expand, Redshift has a massively parallel processing (MPP) data warehouse architecture, parallelizing and distributing SQL operations to take advantage of all available resources. The underlying hardware is designed for high performance data processing, using local attached storage to maximize throughput between the CPUs and drives, and a high-speed, low-latency network to maximize throughput between nodes.
Expanding on the distributed nature of Redshift, its split into the leader node and the compute nodes. The leader node receives queries from client applications, parses the queries, and develops execution plans which it assigns to the compute nodes. The compute nodes execute the query plans and send intermediate results back to the leader node for final aggregation.
AWS has had some hardware level optimizations, which lead to crazy performance gains, i’ve seen some very large redshift clusters, 1+ PB, handle load well. Supporting a Redshift does require some database expertise, and some operations folks to keep things running. Long running queries or computationally heavy queries like ones in this post (LINK TO RAPTOR SQL POST), mean your cluster could have performance degradation.
Let’s take a look at some of the key features that Redshift offers and how they make the life of of data professionals easier:
AWS Services Integration: Redshift integrates seamlessly with other AWS services such as S3, DynamoDB, EMR, Glue, Quicksight, and Data Pipeline. This allows data engineers to EASILY build comprehensive data solutions leveraging the full power of the AWS ecosystem. The integration between the AWS data services are HUGE timesavers. S3 and Redshift is the most important, as Data Lakes tend to be built on S3 as the object storage, more on this later.
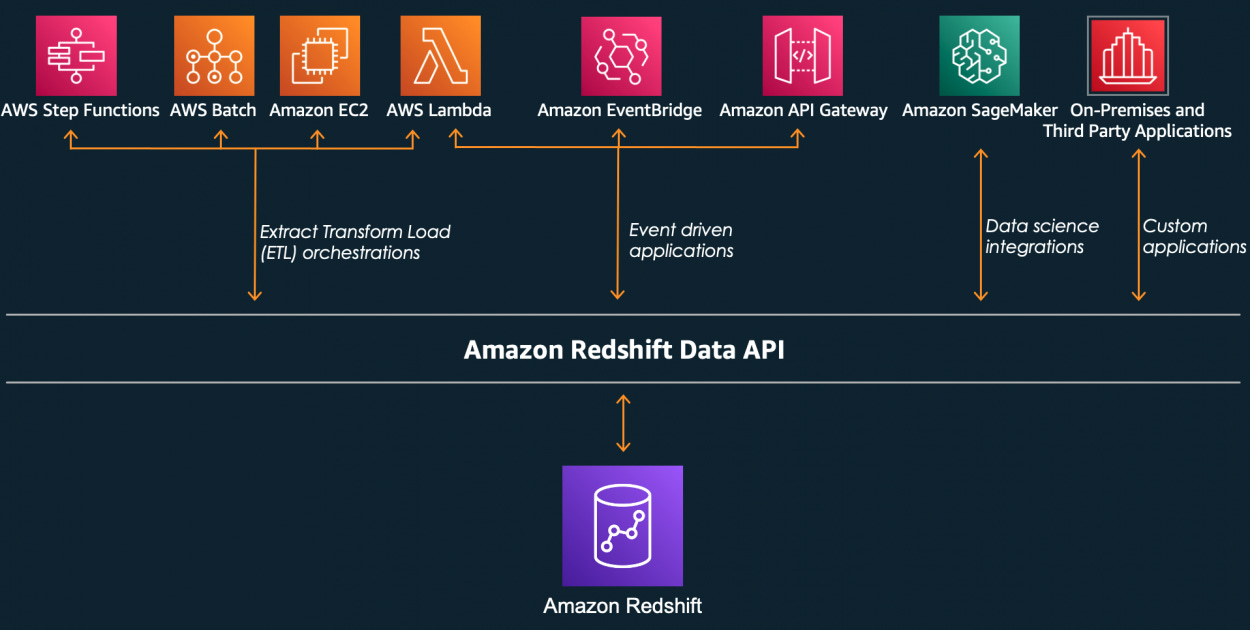
Some of the integrations possible Concurrency Scaling: This feature allows Redshift to add additional cluster capacity when you need to support more concurrent users or complex queries. For data engineers and data ops people, this means they can manage high demand periods without manual intervention. Data scientists can run complex queries without worrying about being yelled at by a data engineer.
Data Sharing: Redshift allows for live data sharing across Redshift clusters. This is beneficial for data scientists as they can easily share their datasets with others for collaborative analysis. Data engineers can also use this feature to provide access to data across different teams. This is a great feature to ‘tear down data silos’ and pipe datasets across to other teams easily. Of course there needs to be some governance here if the datasets are sensitive.
Data Exchange: This feature allows secure and governed sharing of data across AWS accounts either within or outside your organization. Similar to data sharing, but one key caveat, datasets can be purchased. Data scientists can use this feature to access purchase datasets for their analyses. Keeping this within AWS allows your data scientists to get the data rather quickly and start looking for insights.

How this Data Exchange might look Serverless: Redshift's serverless architecture allows data engineers to focus more on data analysis and less on managing servers. It also means that data scientists can run their analyses without worrying about infrastructure management. Serverless can be a great choice for quickly getting a data org up and running, but also reducing some of the operations and undifferentiated infrastructure management. Remember, data scientists are creating insights hopefully profit from those insights, them or other people spending time managing servers is not driving revenue. I just wrote a post on serverless and serverfull:
Serverless vs Serverfull
·On the precipice of another Crusade the software development community remains divided. To have servers or not have servers? This seems to be one of the golden questions of our time. Yes, I did just make up the word serverfull. Much like many arguements people are either on one side or the other. People seem to be losing nuance on where there are use cases for serverfull services like EC2 and where serverless services like ECS, EKS, (in fargate mode), or Lambda make a lot of sense.
Query Editor V2: This is a web-based SQL editor for running queries on Redshift and viewing the results. This can be a handy tool for data scientists for quick data exploration and ad-hoc queries to confirm or dispel any suspicions.
RA3: RA3 nodes allow you to scale and pay for compute and storage independently, enabling you to size your cluster based more on your compute needs. This is beneficial for data engineers as they can optimize the system based on the specific needs of their data workloads. Nice feature here that allow for some use-case specific optimizations. Usually the case is that you need more compute to crunch some complex queries.

Redshift ML: This feature allows data scientists to create, train, and deploy machine learning models directly in their Redshift cluster using SQL commands. This can greatly simplify the process of developing and deploying ML models for data scientists. If there’s one thing i love, its making the life of data scientists easier. This is one cool feature that can streamline ML model development. Of course there is always Sagemaker and the suite of ML tools that AWS offers.
Redshift Reliability: Redshift has built-in fault tolerance and has been designed for high availability. This ensures that data engineers and scientists can rely on Redshift for their critical data workloads. Creating highly-available and fault tolerant databases is one of the hardest feats to accomplish in data engineering. That is why what AWS has done with Aurora and Redshift is so incredible. Data stores are the backbone of modern applications, and you cant have issues with availability at the data tier level. If you want to know more about how this was accomplished with Aurora read my post on it:
AWS RDS Aurora: What Makes it Special
·
hello avatars, today we have a deeper look into a fantastic managed service offered by AWS: AWS RDS Aurora. Aurora is a fully managed database service compatible with PostGress and MySQL. Aurora is the default choice for many architects and its highly performant. Not using and understanding Aurora can open your applications up for downtime and incidents. This is not an exhaustive dive into Aurora, some things will not be covered, but you will know enough about the internals of Aurora to
Analyze all data: Redshift supports both structured and semi-structured data types, including JSON, Avro, ORC, Parquet, and more. This allows data engineers and scientists to analyze all their data in one place without needing to move or transform it.
Turbo Note: Personally, our firm has decided to use Parquet, for our data lake. Read more about Parquet here. Also, its pronounced par-kay.
Price Performance: With Redshift, you pay for what you use. It provides the option to pause and resume your clusters, allowing you to pay only for what you use, which can lead to significant cost savings. As mentioned you can also go serverless depending on your use case.





Redshift Architecture
Usually Redshift is one of the big parts in your data lake. The purpose of the data lake is to create a single data repository for your organization. Obviously that includes a lot of technical capabilities. The high level view, looks like this:
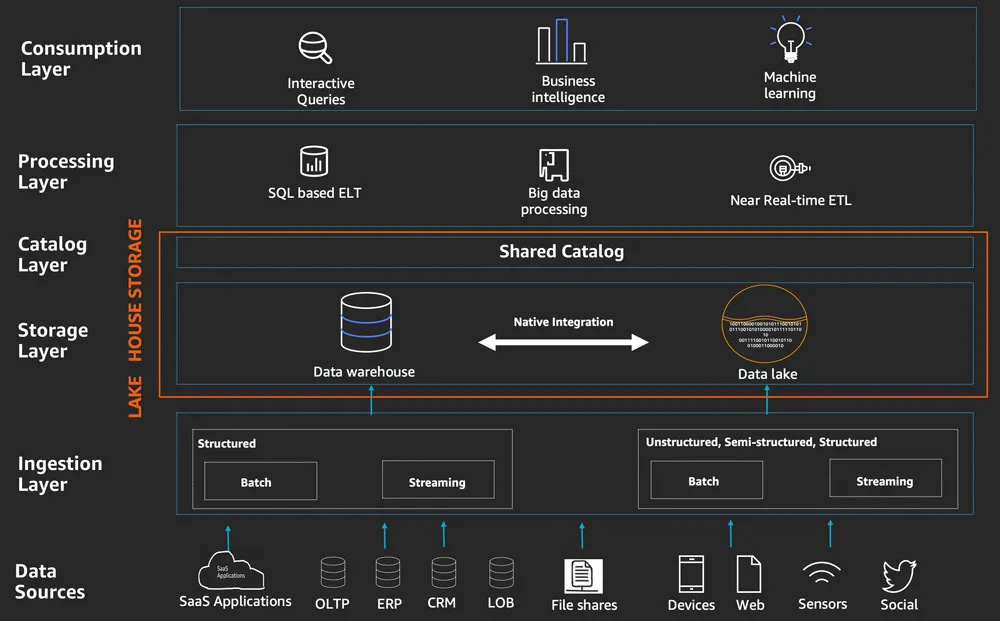
The consumption layer is where we need to make this data available to data scientists. Redshift makes that very easy with the SQL Query Editor and the integrations with other AWS services, like Redshift Federated Queries which allow you to query files in S3.
Concretely, a data lake could look something like this:
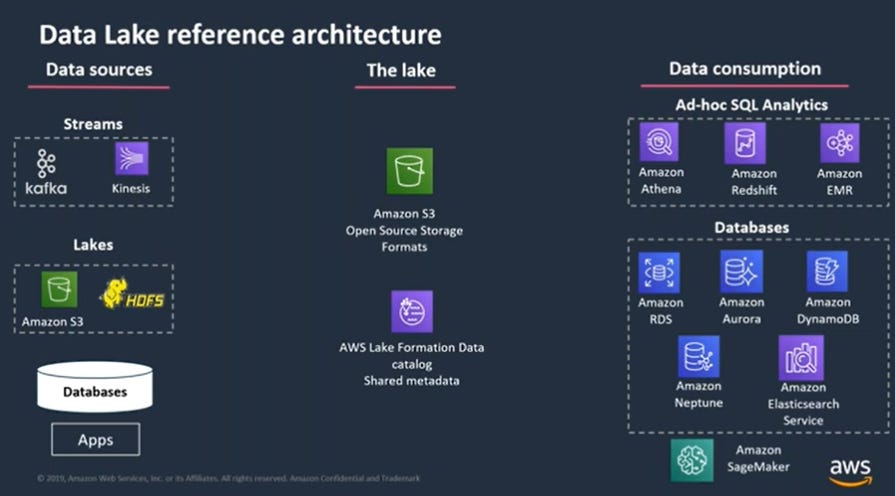
Conclusion
Redshift provides a rich feature set that expedites the data lifecycle, delivering data into the hands of data scientists more quickly so they can generate insights and drive profits. Its seamless integrations with other AWS services enable data engineers to rapidly create data pipelines and expose datasets downstream to data scientists.
In the context of a data lake, Redshift plays a pivotal role. It provides a platform for executing complex analytic queries against petabytes of structured and unstructured data, making it an integral part of any data lake strategy. With its high performance, scalability, and cost-effectiveness, Redshift is a go-to choice for businesses of all sizes.
In conclusion, Redshift is not just a data warehouse; it's a powerful engine for *profit*. Redshift facilitates easy and quick access to data for data scientists. Data holds immense value, and Redshift is the tool that helps unlock that value.